The One Manager Skill That Persists
Of style timing, sector timing, and stock picking, only stock picking carries forward.
Conrad Gann · RiskModels | Blue Water Macro Corp · White paper · v1.2 · June 2026
Abstract
An allocator who has already chosen a mandate — say, a large-cap US stock fund — still must pick which fund, and is really paying for one of three things: the manager's ability to time styles, to time sectors, or to pick individual stocks. We test, out of sample, which of the three actually repeats. A bottom-up decomposition rebuilds each fund's return from its point-in-time holdings and strips market, sector, subsector, and Fama–French style stock by stock; we then rank diversified US equity funds each year on their trailing skill at each, and watch the top quintile versus the bottom over the next year, across roughly fifteen non-overlapping annual rebalances.
The result is unusually clean: recent style-timing success is a weak, directionally negative forward signal (t ≈ −2.1, not significant at the 5% level two-sided in this sample), sector timing is not distinguishable from noise (t ≈ 0), and only stock-picking persists — as a gross, holdings-derived, between-fund signal on a large-cap US-blend cohort — a forward top-minus-bottom-quintile gap of about +2.7 percentage points (t ≈ 2.8, annual non-overlapping). Crucially, it persists as durable between-fund quality: good pickers stay good. It is not a market- or factor-timing signal an allocator must catch in motion, but a durable level effect that separates one fund from another. This is a signal for ranking managers inside a chosen mandate — identifying which funds carry better forward odds — not a claim that active management broadly beats indexing. We then position the work against how the industry evaluates managers — rating shops, returns-based scorekeepers, Morningstar, and the academic literature — and argue that the specific synthesis here (holdings-based, factor-and-sector-neutral by construction, persistence-validated out of sample) is one we are not aware of in a published manager-selection framework.
Contents. (1) What a fund's own documents reveal · (2) What its holdings reveal · (3) The persistence test: definition and scoring · (4) What persists: the three manager skills · (5) Ranking managers on the one skill that persists · (6) How the industry evaluates managers — and where RiskModels fits · (7) Implications for allocators · Appendix A (methodology) · Sources.
Key findings & allocator implications
- Only stock-picking persists. Of style timing, sector timing, and stock-picking, two do not repeat out of sample — recent style-timing success is a weak, directionally negative forward signal (t ≈ −2.1, not significant at the 5% level two-sided in this sample), sector timing is not distinguishable from noise (t ≈ 0) — and only individual stock-picking carries forward.
- The headline number. The forward top-minus-bottom-quintile gap in style-and-sector-neutral stock-picking is about +2.7 percentage points, with an annual, non-overlapping reliability of t ≈ 2.8. This single statistic is used consistently throughout the paper.
- It is durable quality, not timing. The persistence is a between-fund level effect (the within-fund / timing component is essentially zero): some funds are simply, persistently better pickers.
- What an allocator does with it. Inside a chosen mandate, rank candidate funds on their style-and-sector-neutral stock-picking, favor the top quintile, and hold — treat it as a cohort ranking signal that improves forward odds, not a guarantee about any single fund.
- A sharper residual. An adaptive, cost-aware variant — L-Star — lets each stock choose how deeply to hedge point-in-time rather than always hedging to the deepest level. Once style is stripped, it sharpens the ranking signal — a forward gap of about +3.0pp versus +2.2pp for the fixed residual on a common sample — but it is a refinement to the ranking feature, not the headline persistence result (Section 5).
A separate question — which residual best ranks managers on that skill — is addressed in Section 5; its t-statistics are not the persistence headline and are not interchangeable with the +2.7pp / t ≈ 2.8 result above.
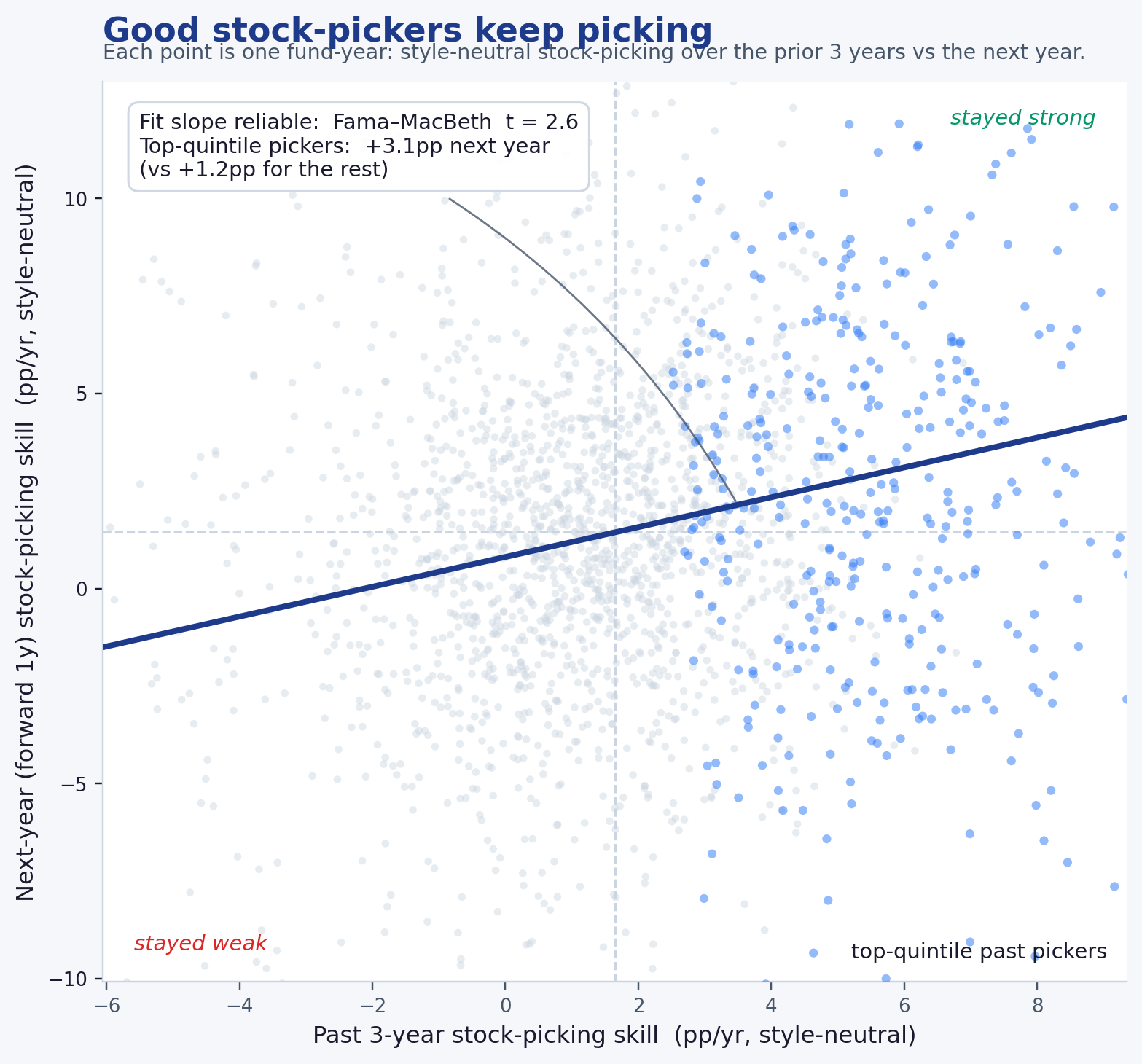
1. What a fund's own documents reveal
Take two of the largest, most storied active US equity funds. Their public materials state what they aim to do in a single sentence each:
- Fidelity Contrafund (FCNTX, ~$146B): "The investment seeks capital appreciation." The strategy adds that it "invests in securities of companies whose value the advisor believes is not fully recognized by the public … in either 'growth' stocks or 'value' stocks or both," selected by "fundamental analysis."
- American Funds The Growth Fund of America (AGTHX): "The fund's investment objective is to provide you with growth of capital," pursued through a "flexible" mix of "traditional growth stocks as well as cyclical companies and turnarounds."
Both descriptions are accurate — and both are nearly content-free for the purpose of telling two skilled managers apart. "Seek capital appreciation through fundamental analysis of growth or value stocks" could be printed on the cover of almost any active equity fund.
The numbers the fund companies publish reduce to just two things, and neither isolates skill:
| What the materials disclose | What it actually tells you |
|---|---|
| Total return (shown against the S&P 500) | How much the fund made. A high number could be market, style, sector, luck, or genuine selection — the document cannot say which. |
| A market beta — sometimes, and loosely defined | AGTHX's own page lists a beta of 1.18 vs the S&P 500 over a trailing 3 years. But the S&P 500 is not its style benchmark, the window is arbitrary, and one beta collapses every kind of exposure into a single number. Contrafund's fact sheet shows no beta at all — only a 1-to-5 "risk level" dial and a category-relative Morningstar risk label. |
And even that single beta is more fragile than it looks. Computed from public NAV returns, AGTHX's beta to the S&P 500 is 1.20 over a trailing 3 years — reproducing the 1.18 the page reports — but a different window gives a different answer, and over rolling 3-year windows since 2006 it has wandered by roughly a third of its own value:
| Trailing window | AGTHX beta vs S&P 500 | FCNTX beta vs S&P 500 |
|---|---|---|
| 1 year | 1.21 | 0.92 |
| 3 years | 1.20 | 1.02 |
| 5 years | 1.13 | 1.03 |
| 10 years | 1.07 | 1.02 |
| rolling-3yr range, 2006–26 | 0.90 – 1.20 | 0.82 – 1.11 |
So "beta 1.18" is not a property of the fund; it is the answer for one window, and the window is a choice that swings the number by ~0.3. The materials never convey this — AGTHX at least labels its window (3 years), while Contrafund's fact sheet reports no beta and no window at all. A statistic this sensitive to an undisclosed (or unstated-as-arbitrary) modeling choice tells an allocator very little.
So from the offering materials an allocator can see, at best, how much the fund returned and roughly how much it moves with the market — and even that market sensitivity is poorly anchored. What they cannot see is the thing they are actually buying: did the return come from style, from sector bets, or from picking individual stocks?
2. What their holdings reveal
There is far more information available — it just isn't in the marketing. Every US mutual fund reports its full portfolio holdings every quarter to the SEC. The fact sheets even print a snapshot: Contrafund's latest filing shows 25.8% technology and 22.2% communication services, with a top ten running Meta, NVIDIA, Amazon, Berkshire Hathaway, and Alphabet. But that is a single static picture of what they hold today — not how those positions performed, and not why.
The RiskModels Holdings-Based Return Decomposition turns the full history of those quarterly positions into the answer. It is bottom-up: because we know what each fund held at each point in time, and we have already decomposed every underlying stock's daily return into its market, sector, subsector, and style layers, we can rebuild each fund's realized return stock by stock and split it into the pieces the fund documents cannot:
- how much came from simply being in the market,
- how much from style — a persistent size or value lean,
- how much from sector and subsector tilts,
- and how much from picking individual stocks — the residual left once the first three are stripped away.
The decomposition is flexible: strip out sectors (the industry cascade) or style (the Fama–French cascade), or both, and what remains is the cleanest available measure of a manager's stock-selection contribution. That is the piece an allocator is really underwriting — and the rest of this paper puts it to the test.
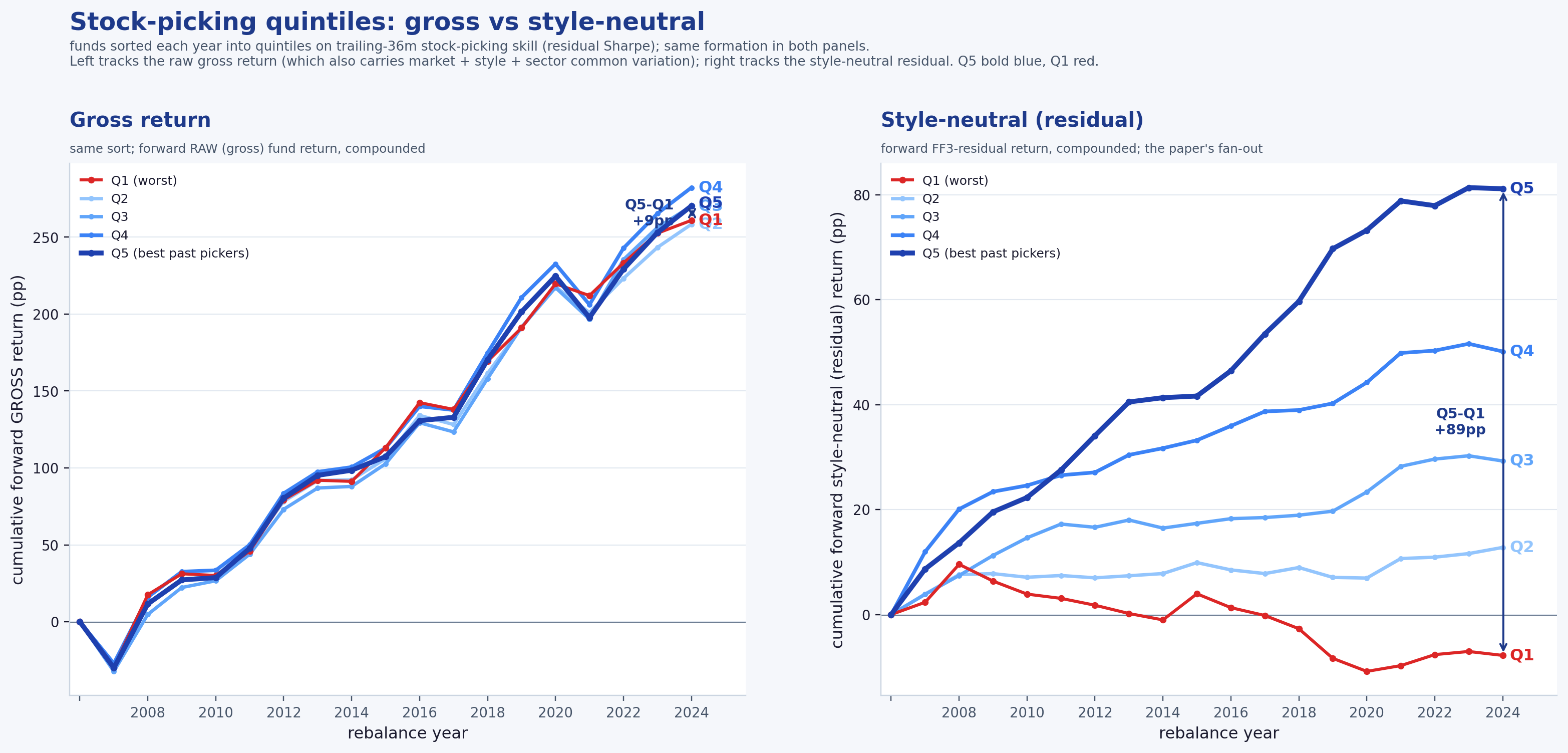
One picture frames where this leads. Place every diversified US equity fund on two axes: how much of its residual is just style premium (horizontal), and how much genuine, style-neutral stock-picking is left once that premium is stripped (vertical). The managers an allocator actually wants live in the upper-left — real selection, little reliance on a style tilt. The lower-right is where a value or growth bet is doing the work that looks like skill. Earning the right to read that vertical axis — and showing that it is the only axis that predicts the future — is what the rest of this paper is about.
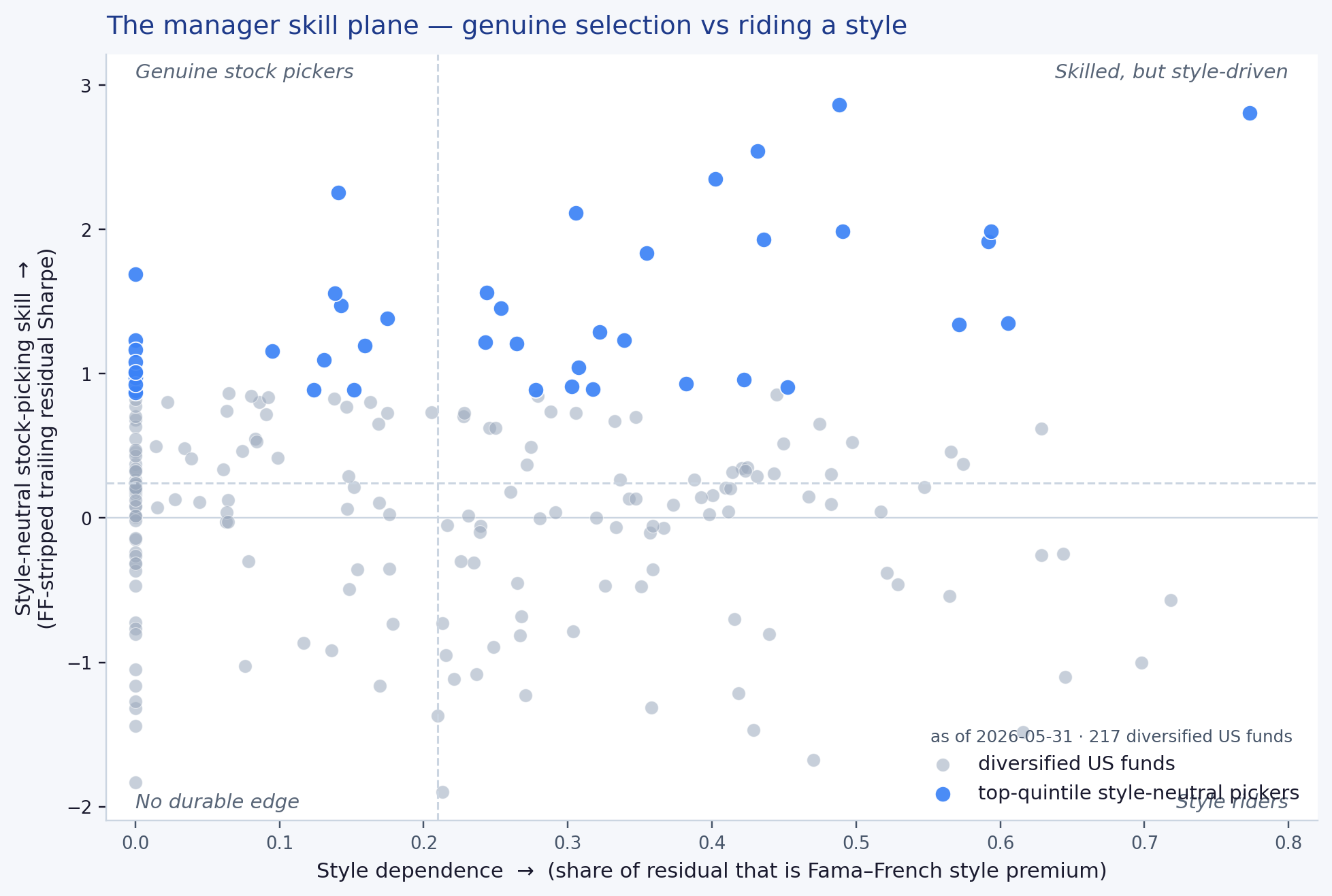
How this differs from the conventional tools
The established tools stop short of isolating stock selection:
| Tool | What it gives you | Isolates genuine stock-picking? |
|---|---|---|
| Holdings look-through / "X-Ray" (Morningstar) | current sector / style-box / region weights | No — exposures, not return, not skill |
| Brinson attribution | active return → sector allocation + within-sector selection | Partial — "selection" still contains style/size bets (no factor control) |
| Morningstar Direct Global Risk Model | factor exposures + a security "specific return" (8 style + 11 sectors, 5-yr rolling regression) | Closer — but a flat factor model: 11 sectors, no subsector, noisy multi-year betas |
| RiskModels (this work) | return → market / style / sector / subsector / stock-specific, then persistence-tested | Yes — bottom-up, one level deeper (to subsector), and validated which part is selectable skill |
Two differences matter. First, ours is bottom-up and goes one level deeper — to subsector: it removes the actual market, sector, and subsector (one level below the industry's 11 sectors) peer-group return directly, then strips Fama–French style — rather than regressing each stock on a fixed set of broad factors. Second, and more important, it adds the step none of these tools provide: it tests, out of sample, which decomposed components actually persist — and (as the rest of this paper shows) only stock-picking does. A risk model reports what happened; it does not tell an allocator that the selection piece is the only one worth selecting on.
Related to Active Share, but different. This work is related to Active Share — the widely used measure of how much a manager's holdings differ from its benchmark — but it asks a different question. Active Share asks how different a manager is from a benchmark; this paper asks which part of that difference actually persists: style, sector, or stock selection. (Active Share is taken up directly in a companion paper.)
3. The persistence test: definition and scoring
An allocator has already chosen a mandate ("I want a large-cap US stock fund") and now must pick which fund. They want a manager with genuine, repeatable skill, not one who got lucky or rode a trend. So we ask, of everything a manager actually does, which parts repeat — because only the parts that repeat are worth selecting on. For each layer of the decomposition above, the test is a single, plain question: if a manager was good at it over the past 3 years, are they still good at it over the next year?
How to read the score. Each year we rank funds into five buckets by their past skill at one thing, then watch what the top bucket does versus the bottom bucket over the next year, repeated across roughly fifteen years. The "reliability score" — a t-statistic of that gap across years — summarizes how dependable the gap was. We report simple annual, non-overlapping t-statistics to avoid overstating significance. Exactly one of three things happens:
| Score | What it means | What an allocator should do |
|---|---|---|
| +2 or higher | Persists — top stays top | Select on it |
| Between −2 and +2 | No pattern — mostly luck | Ignore it |
| −2 or lower | Reverses — top flips to bottom | Don't chase it (it backfires) |
A brief note on which statistic is the headline. Throughout, the persistence result is reported as a simple annual, non-overlapping t-statistic — chosen for legibility and because it does not overstate significance. (The fuller methodological history behind this choice, including statistics from an earlier framing that did not survive adversarial re-review, is documented in Appendix A.) The headline persistence number is the +2.7pp forward top-minus-bottom-quintile gap at t ≈ 2.8 reported in Section 4. A separate and distinct question — which residual best ranks managers on the stock-picking skill — appears in Section 5 and carries its own, larger t-statistics; those are not the persistence headline and the two should never be conflated.
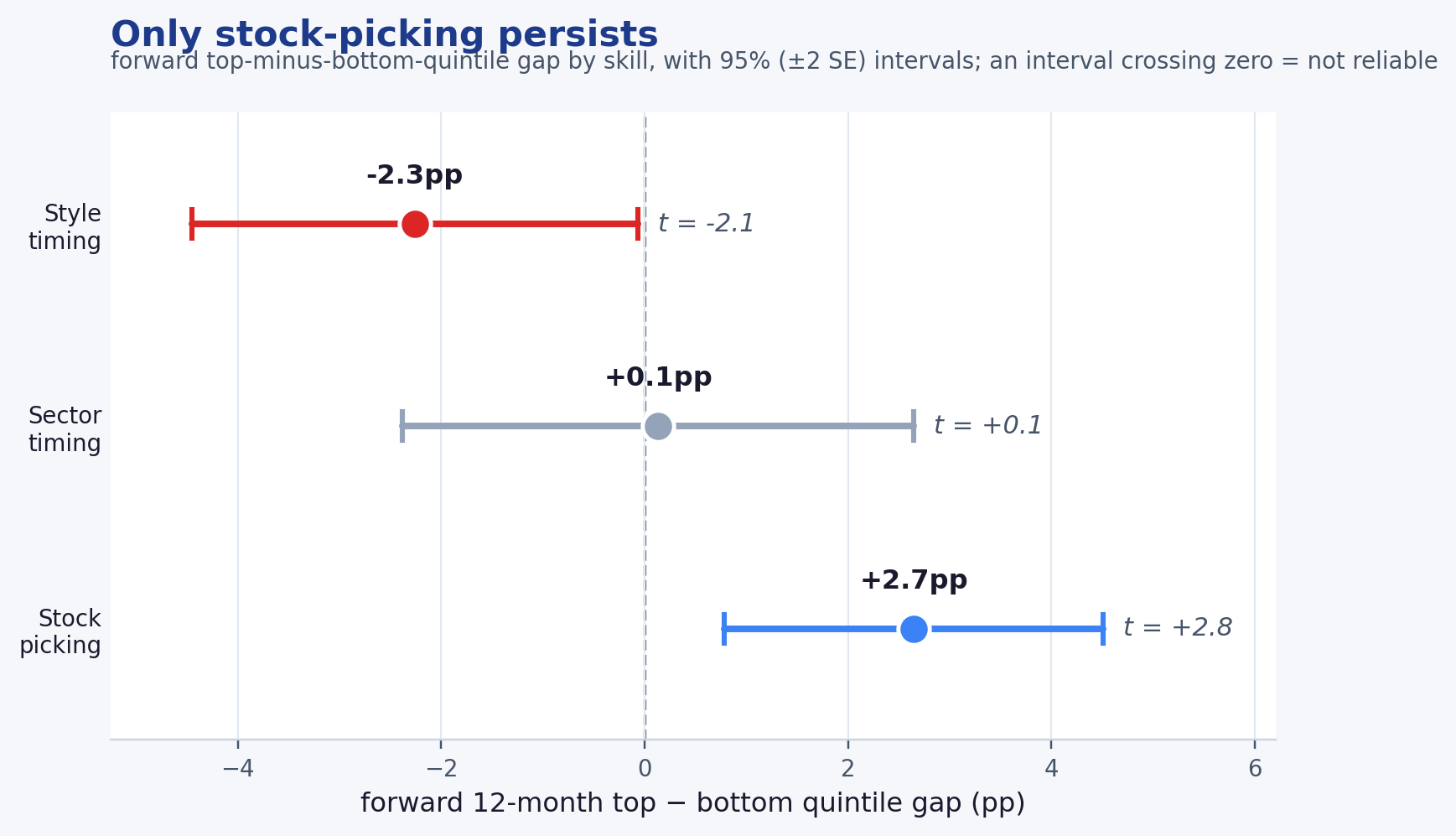
4. What persists: the three manager skills
| Manager skill | In plain terms | Forward top−bottom gap | Score | Verdict |
|---|---|---|---|---|
| Style timing | Leaning into value/small at the right time | −2.3pp | −2.1 | Weak/negative — recent style-timing success does not carry forward and is, if anything, a slight negative signal (not statistically reliable) |
| Sector timing | Overweighting the right sectors at the right time | +0.1pp | +0.1 | No pattern — sector bets don't repeat (held up even among the biggest sector-bettors) |
| Stock picking | Picking individual winners within sector & style | +2.7pp | +2.8 | Persists — the one real, selectable skill |
Of the three things an allocator might pay an active manager for, two do not repeat — recent style-timing success is a weak, directionally negative forward signal (t ≈ −2.1, not significant at the 5% level two-sided in this sample) — and only individual stock-picking carries forward, at a forward top-minus-bottom-quintile gap of +2.7pp with annual, non-overlapping reliability of t ≈ 2.8. All three skills are measured the same way, in one unified, annual, non-overlapping run over roughly fifteen years.
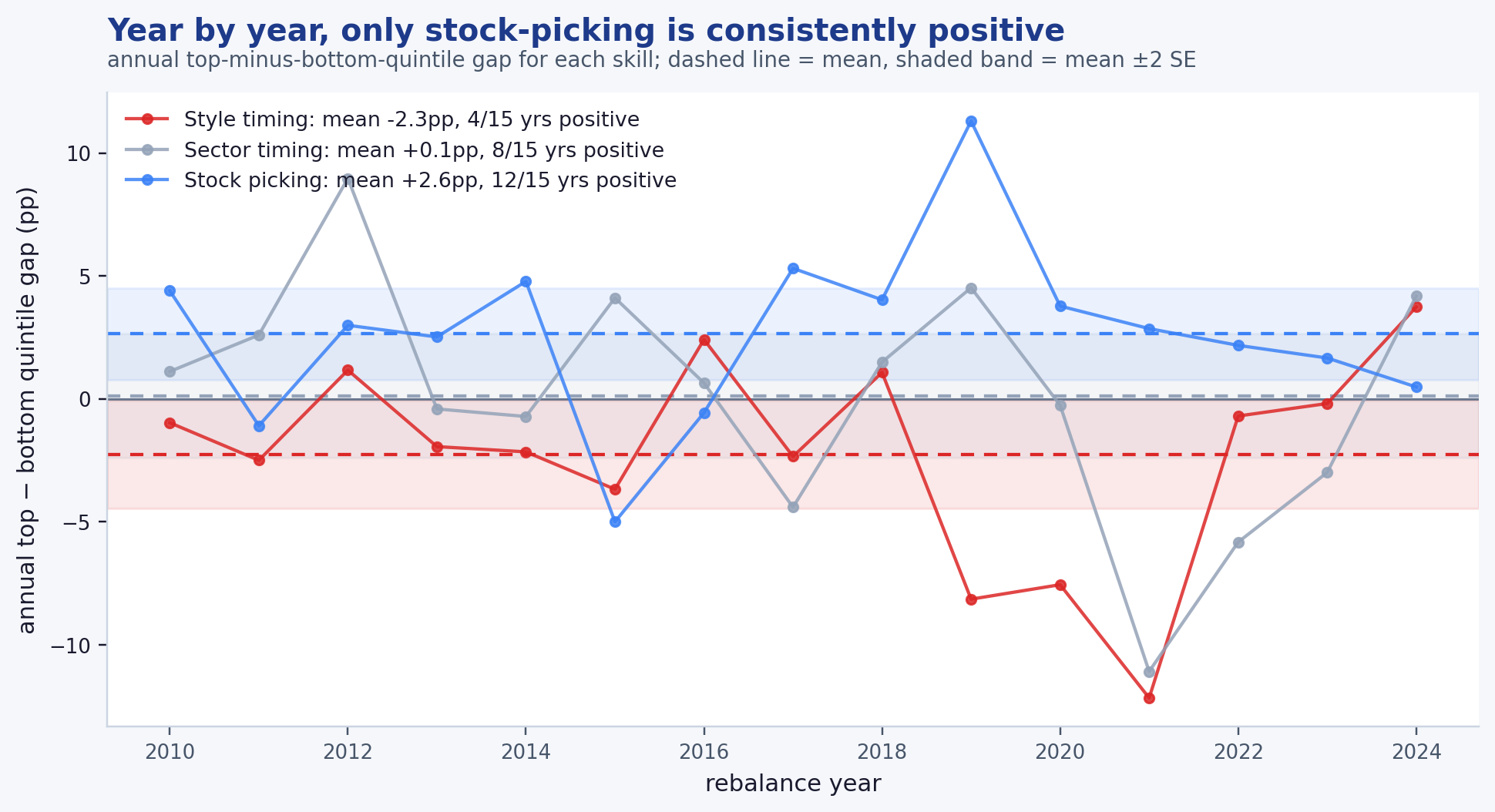
How reliable is "t ≈ 2.8"? A transparency exhibit. Because the test is annual and non-overlapping, the whole result rests on roughly fifteen rebalances — a small sample by design, and we show every year of it rather than only the summary. The figure below plots the year-by-year top-minus-bottom-quintile gap for all three skills, with each skill's mean and a ±2 SE band. The pattern is consistent rather than driven by one or two extreme years: stock-picking is positive in 12 of 15 years (mean +2.6pp), style timing is positive in only 4 of 15 (mean −2.3pp), and sector timing is positive in 8 of 15 (mean +0.1pp) — a coin flip. The result is stronger in the back half of the sample (post-2015 gap +3.5pp, t ≈ 3.0; pre-2015 +1.4pp, t ≈ 0.9, on six rebalances). We read the early-half weakness as small-sample plus the thinner pre-2019 N-Q holdings lineage rather than a structural break, but flag it.
Reading the statistics honestly: effective sample size. Two cautions belong with any t-statistic built on ~15 annual observations. First, the trailing ranking feature is persistent (one-year rank autocorrelation ≈ 0.82) — which is the persistence we are documenting, not a defect. The statistic itself is built on the non-overlapping annual Q5−Q1 gap series, whose own year-to-year autocorrelation is ≈0.1, so the simple annual t uses the appropriate denominator. A stationary block-bootstrap on those gaps (respecting their mild dependence) gives P(mean ≤ 0) ≈ 0.001. We retain humility about the modest 15-rebalance sample, but the feature autocorrelation does not deflate this t. Second, the design tests three skills plus a ranking bake-off; this multiple-comparison context was conceptually pre-specified (the three skills are the exhaustive decomposition of what a manager does, not a search over many candidate signals), but it is worth stating plainly — and the stock-picking result survives it: its raw two-sided p ≈ 0.013 becomes p ≈ 0.039 under Bonferroni, Holm, and Benjamini–Hochberg correction across the three skills, still significant at the 5% level. The robustness comes less from the nominal t than from the shape of the result: one skill reliably positive, one reliably negative, one flat, consistent year over year, and — as the next paragraph shows — concentrated in a between-fund level effect that a static sort recovers.
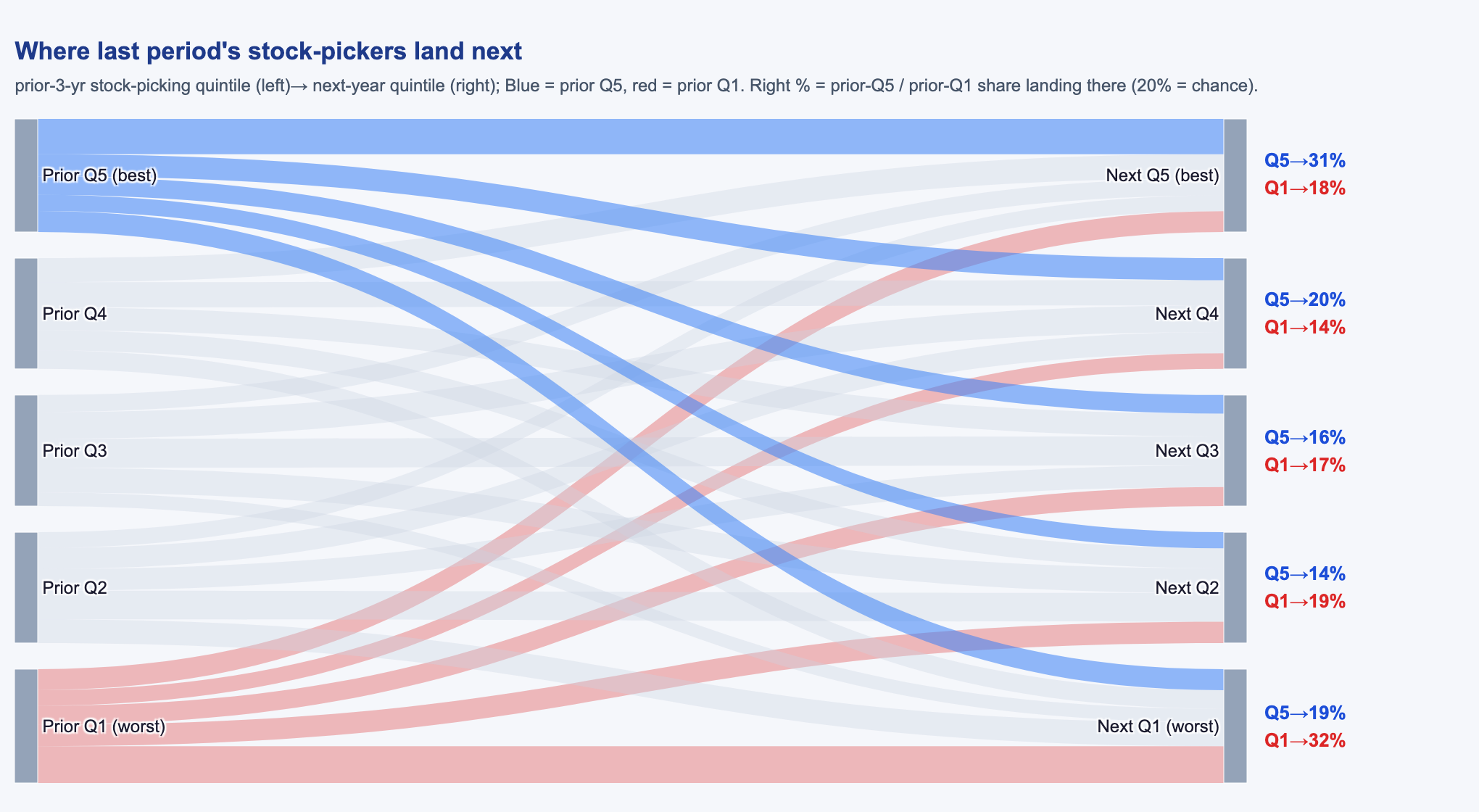
It is durable quality, not timing. How stock-picking persists matters for what an allocator should do with it. Decompose each fund's stock-picking into a between-fund part (some funds are simply, persistently better) and a within-fund part (a fund turning its picking on and off through time). The persistence lives almost entirely in the between-fund part; the within-fund / timing component is essentially zero, and a static, full-sample-mean sort — which carries no timing information at all — reproduces the large majority of the spread (Appendix A.5). In plain terms: good stock-pickers stay good. The actionable form is identify the persistently good and hold — not chase whoever is hot this quarter — and this is also why the modest effective sample size is less worrying than it first appears: a level effect is exactly the kind of result that a static sort confirms independently of the year-by-year timing series.
Recent style-timing success is a weak, directionally negative forward signal, and it isn't a factor-reversal artifact. Funds that recently profited from a style lean tend to give it back (t ≈ −2.1, not significant at the 5% level two-sided in this sample). We checked whether this is just the style factors themselves mean-reverting year to year — it is not: the style factors do not meaningfully mean-revert at the annual horizon, and the negative signal lives in the timing component, not in a static value/growth tilt. A persistent style lean neither helps nor hurts selection; recent style-timing success is specifically a weak negative signal. The allocator conclusion is the same either way: do not credit a manager for recent style timing.
Sector timing is not distinguishable from noise in this sample (t ≈ 0). Sector/subsector timing shows no persistence in the full cohort. One natural worry is that closet-indexers dilute the measure — funds that barely tilt add noise. We re-ran the test among the funds that actually make the biggest sector bets (sorting directly on the size of their sector-timing contribution). It did not firm up; if anything it drifted slightly negative and stayed insignificant. Both timing skills fail to persist even among the funds that most actively do them — which is the strongest possible form of the negative result. (An earlier active-share filter appeared to lift sector timing toward significance, but that turned out to be a confound: active-share-versus-SPY flags funds that differ from the index at the stock level — i.e., good stock-pickers — so stock-picking skill was leaking into the imperfect sector-timing measure. The direct sector-bet-size filter removes the confound.)
5. Ranking managers on the one skill that persists
Section 4 established what persists. This section answers a different and narrower question: given that stock-picking is the skill worth selecting on, which residual best ranks managers on it? The statistics here measure the predictive power of a ranking feature against a fixed skill target — they are not the §4 persistence headline (+2.7pp / t ≈ 2.8) and are not interchangeable with it. A ranking-feature t can be larger than the persistence t because it asks an easier question (rank-order managers) on a different construct (feature-vs-target predictiveness rather than a forward portfolio gap).
There are two ways to strip a fund's return down to "stock picking," and they leave different leftovers, so they give different rankings. We test which ranking best predicts genuine future stock-picking — scoring both against the same fair target: the residual cleaned of both sector and style.
| Rank managers by… | In plain terms | Ranking t | Verdict |
|---|---|---|---|
| Sector-cascade residual | What's left after stripping market / sector / subsector | 3.3–4.2 | Best single signal |
| FF-cascade residual | What's left after stripping market / size / value | 1.4 | Weak for ranking skill |
| Mix of the two | Must look good on both | 3.5 | No better than sector alone — mixing dilutes |
(The "ranking t" column measures how well each feature ranks managers on the doubly-cleaned skill target — a §5 question. It is distinct from, and larger than, the §4 persistence headline of t ≈ 2.8.)
Mixing the two does not help: the two rankings overlap heavily (~0.57 correlation), so the weaker (FF) signal brings little new information but adds its own noise, dragging the blend below the sector cascade alone.
One fairness caveat. The FF cascade is not inherently weak — the comparison above asks it to predict a target that happens to suit the sector cascade better. Stated fairly:
| Question | Answer |
|---|---|
| Did both cascades use the same target? | Yes — the clean, doubly-stripped stock-picking target |
| Is the FF cascade just bad? | No. Predicting its own residual it scores ~2.1 |
| So why only 1.4 above? | Its own residual is propped up by sticky sector positioning (funds keep their sector tilts) — that is positioning, not skill. Strip sector out, as the fair skill-target does, and the prop disappears |
A measurement lesson worth stating plainly. What you strip from the target and what you strip from the ranking feature are different decisions. The right target is style-neutral — genuine skill is what is left once style premium is removed. But the right feature is the raw sector-cascade residual, not a style-stripped one: stripping style from the trailing feature injects rolling-beta estimation noise, and trailing style is non-persistent anyway, so leaving it in is harmless. Best practice is therefore a raw sector-cascade residual feature predicting a style-neutral target — which is exactly the +2.7pp / t ≈ 2.8 configuration headlined in Section 4, and the basis for the screens in Section 7. In one line each:
| Role | What it strips |
|---|---|
| Feature (what you rank on) | Raw sector-cascade residual — market / sector / subsector only; style left in |
| Target (what you score against) | Style-and-sector-neutral residual — market / sector / subsector and Fama–French style stripped |
A sharper residual once style is stripped: the adaptive-hedge cascade
The sector-cascade residual above hedges every stock all the way down to its subsector. A natural refinement is to let each stock choose how deeply to hedge — market only, market-plus-sector, or the full market-plus-sector-plus-subsector — picking the depth that best removes systematic risk for that stock rather than forcing the deepest level everywhere. L-Star — a point-in-time, cost-aware selection layer — chooses each stock's hedge depth to maximize predicted out-of-sample risk reduction net of hedging cost. An adaptive residual variant lets each stock choose its hedge depth point-in-time; in this sample it sharpens the ranking signal once style is stripped, but it is a refinement to the ranking feature, not the headline persistence result.
Three residual variants appear below; each is one line:
| Residual variant | What it is |
|---|---|
| Raw residual | Return left after stripping market only — style and sector premia still inside |
| Full-depth (subsector) residual | Return left after hedging every stock all the way to subsector (the fixed sector cascade) |
| Adaptive (L-Star) residual | Return left after each stock hedges to its own cost-optimal depth (market, +sector, or +subsector) |
As a ranking residual the adaptive variant behaves in a revealing way. On a common 2014–2024 sample (eleven annual rebalances), the forward top-minus-bottom-quintile gap is below. The columns vary how much style is then stripped from the feature — "before style-stripping," with style removed, and with style and momentum removed:
| Residual | before style-stripping | style-stripped | style + momentum stripped |
|---|---|---|---|
| Fixed full-depth (subsector) | +1.2pp | +2.2pp (t 1.6) | +3.0pp (t 2.3) |
| Adaptive depth (L-Star) | +0.3pp | +3.0pp (t 2.1) | +4.0pp (t 2.8) |
The crossover is the point: adaptive hedging trails the fixed residual on the raw number — it optimizes cost-efficient risk removal rather than strict factor-neutrality, so a little more style-correlated return is left in — but leads once that style premium is stripped, and leads by more once momentum is also removed. The adaptive residual is a cleaner read on genuine selection. We verified out of sample that this extra edge is real stock-picking and not sector-timing riding along: purging the forward return of contemporaneous sector and subsector timing leaves the adaptive residual's advantage essentially intact, and a predictive test finds no channel by which the trailing signal could be forecasting future sector timing (Appendix A.9).
(These figures sit on the eleven-year window the momentum leg requires, so their t-statistics are not directly comparable to the §4 headline's longer-window t ≈ 2.8, and the effective-sample caveat of Section 4 applies here too. They establish the relative sharpening from adaptive hedging, not a new headline number.)
Bottom line. Of the three things managers do, recent style-timing success is a weak, directionally negative forward signal (not statistically reliable), sector timing is not distinguishable from noise in this sample, and only stock picking persists — as durable quality, not timing. The cleanest way to rank managers on that stock-picking skill is the sector-cascade residual, and an adaptive, cost-aware version of it (L-Star) sharpens the signal further once style is stripped; the FF cascade and any blend of the two add nothing on top.
6. How the industry evaluates managers — and where we fit
Everyone in institutional manager selection is trying to answer the same question we are — which managers have genuine, repeatable stock-selection skill? The field splits into three camps, and the one thing almost no one does is the thing this work is built on: isolate stock-picking from style and sector bets, and publish evidence that the isolated signal predicts the future.
| Provider | How they evaluate skill | Holdings-based? | Isolates stock-picking from style/sector? | Best published forward stat |
|---|---|---|---|---|
| Qualitative rating shops | ||||
| Mercer | Committee ratings A/B/C on people & process | No | No | None published (proprietary) |
| Aon | Buy/Qualified/Sell + ops + ESG; factor analysis internally | Internally | Internally, not published | None published |
| Wilshire | Qualitative scoring model | No | No | None published |
| Russell | Four P's (People/Process/Philosophy/Performance) + ML screen | No | No | Firm-reported high hit-rate for hire-rated products — blends asset classes, self-reported |
| NEPC | Conviction ratings | No | No | Median large-cap mgr earns less than its fee (active doesn't clear costs) |
| Returns-based scorekeepers | ||||
| Callan | % of rolling periods with positive net excess | No (rejects holdings) | No | Treats Active Share as risk, "not a litmus test" for skill |
| SPIVA (S&P DJI) | Survivorship-free persistence & win-rates on raw return | No | No (single-benchmark, total return) | Top-quartile persistence collapses toward zero within a few years; a large majority of active US funds trail over 5–20 yrs |
| Holdings-based predictors | ||||
| Cambridge Associates | Qualitative + active-share / concentration research | Yes | Partly (active share, not factor-neutral) | Higher active share / concentration → higher subsequent relative return |
| Morningstar — Global Risk Model | 36-factor risk model (11 sectors), security "specific return" | Yes (factor) | Partly (flat factor model) | Validated for risk forecasting, not skill |
| Morningstar — "best predictor" (Rekenthaler / Cohen-Coval-Pastor) | "Company they keep" — overlap with funds that have strong records | Yes | Carhart 4-factor alpha (no sector) | ≈ +330 bps top-vs-bottom subsequent alpha (global equity funds, 2004–2018) |
| RiskModels (this work) | Bottom-up return decomposition through full PIT holdings | Yes | Yes — market + sector + subsector + style stripped | +2.7pp forward Q5−Q1, annual t ≈ 2.8, persistence-validated |
Three things separate the camps. Qualitative rating shops (Mercer, Aon, Wilshire, Russell, NEPC) rate managers on organization, people, process, and philosophy — thoughtful frameworks, but largely proprietary, and almost none publishes a quantified track record showing its top-rated managers add alpha. The most candid public number from the group is NEPC's: the median large-cap manager does not earn back its own fee. Returns-based scorekeepers (SPIVA, Callan) measure persistence and win-rates on raw total return against a single benchmark; they are rigorous and survivorship-free, and they supply the industry's most-quoted facts — raw top-quartile persistence collapses toward zero within a few years, and most active US equity funds trail over long horizons — but by construction they cannot separate skill from style or sector tilts. Holdings-based predictors (Cambridge, Morningstar) come closest: Cambridge ties higher active share and concentration to higher subsequent relative return, and Morningstar's Rekenthaler "best predictor" — the Cohen-Coval-Pastor "company they keep" consensus — is a holdings-based, style-adjusted quality-of-holdings score with a published forward spread.
The deeper distinction, though, is about what each approach can isolate and validate:
- Returns-based persistence tests don't isolate stock selection. A fund's record blends market, style, sector, and selection; raw persistence tests cannot say which component repeats.
- Holdings look-through shows exposures, not validated persistence. X-Ray and risk models report current weights or factor loadings — what a fund is, not which part of its skill carries forward.
- This work tests decomposed components out of sample. We strip market, sector, subsector, and style by construction, then ask which decomposed component persists — and report that only stock-picking does.
Where RiskModels Fits
The published holdings-based forward spreads (Cambridge, Morningstar) and our stock-selection result are broadly the same order of magnitude — reassuring, but not a controlled comparison: the studies differ in universe, period, signal construction, and alpha definition (Morningstar scores a fund by the track records of other funds holding the same stocks; Cambridge uses active share; ours is the manager's own realized style-neutral residual). The honest statement is "same order of magnitude," not "validated against each other." Full study-by-study differences are in Appendix A.6.
We did run one controlled head-to-head: we implemented the non-proprietary Cohen-Coval-Pastor "company they keep" consensus signal on our own cohort and period and raced it against our residual signal. On that homogeneous large-blend cohort our residual signal sorted future skill while the consensus signal did not. We are careful not to overclaim: the consensus mechanism is handicapped on a homogeneous cohort — when nearly every fund holds the same mega-caps, "the company they keep" is almost identical across funds, so it cannot discriminate, and it needs the broad, heterogeneous universe Morningstar tested it on. The fair reading is different regimes — for the specific decision an allocator faces, picking among large-blend US funds that look alike on paper, our residual signal works where the consensus cannot — not "we beat Morningstar everywhere."
The specific synthesis. Each building block of this method is established — holdings-based selection signals, factor neutralization, out-of-sample persistence validation.
We are not aware of a single incumbent product or published manager-selection framework that combines all of: a signal that is holdings-based, factor- and sector-neutral by construction, and validated out of sample on which decomposed component persists.
The incumbents each fall short on one leg of that combination. Cambridge uses active share (not factor-neutralized); Morningstar's best predictor is style-adjusted but not sector-decomposed, and its risk model stops at 11 sectors and is validated for risk, not skill. Our distinctive contributions are (1) published, significance-tested evidence of which component persists — the principal edge, not granularity; (2) full factor-and-sector neutralization down to subsector; and (3) transparency — a decomposition an allocator can reproduce through the underlying holdings rather than a proprietary rating. The extra subsector depth, tested head-to-head against a Morningstar-like sector-only version, is a reliability refinement (it steadies the year-to-year ranking) rather than a step-change in the size of the edge (Appendix A.6); we lead with the persistence-validation and transparency, not the granularity.
7. Implications for allocators
The practical implication is narrow and usable. When you have fixed a mandate and are choosing among funds inside it:
- Do not select on recent style-driven returns. A fund that just had a great year because value (or growth, or small-cap) had a great year is, if anything, a slightly negative forward signal (t ≈ −2.1, not statistically reliable in this sample) — don't credit recent style timing.
- Do not select on recent sector bets. Sector timing is not distinguishable from noise in this sample (t ≈ 0), even for the managers who bet hardest on it.
- Do select on style-and-sector-neutral stock-picking, and treat it as durable quality. It is the one component that carries forward, and it carries forward as a level — good pickers stay good — so the right behavior is to identify them and hold, not to chase whoever is hot.
How an allocator uses this signal in practice
A concrete decision framework, for choosing among funds inside an already-chosen mandate:
- Hold the mandate fixed. The signal ranks managers within a comparable cohort (e.g., large-cap US blend). It is not a tool for deciding active-versus-passive or for crossing mandates.
- Score each candidate on its trailing style-and-sector-neutral stock-picking — its sector-cascade residual over a trailing multi-year window, point-in-time (Section 5; Appendix A.2).
- Favor the top quintile and avoid the bottom. The forward edge is concentrated at the top of the ranking; the bottom is where style- and sector-driven records cluster.
- Hold, don't chase. Because the skill is durable between-fund quality, the right cadence is slow — re-rank periodically and replace only on a sustained drop, not on a single soft year (year-over-year top-quintile retention is roughly 59%; Appendix A.7).
- Treat it as odds, not certainty. Top-quintile membership raises forward odds (top-quintile funds stay top-quintile 31% of the time versus 20% by chance); it does not guarantee any single fund will outperform. This is a cohort ranking signal.
Limitations & scope
We lean into the transparency of this work as a strength, which means stating its limits plainly:
- Gross, not net; and the Berk-Green caveat. The signal lives on the gross, holdings-derived side, where skill demonstrably survives. Whether that skill reaches the investor is a separate question: skilled managers may capture the rents themselves through fees or asset growth (Berk-Green). Nothing here claims most active managers beat their benchmark net of fees — the returns-based evidence that most do not is real.
- Cohort scope. The result is established on a diversified US large-cap equity cohort. We do not extend the headline to sector funds, international, small-cap-only, or non-equity mandates; the framework is portable, but the specific numbers are not.
- Survivorship and backfill. While the security-level cascade covers ~6,300 securities including delisted names, the fund cohort is drawn from funds extant at the panel's final date and back-filled through history — it does not include funds liquidated, merged, or renamed before the panel end, and so carries survivorship and backfill bias. We bound it with survivorship-hardened re-runs (fixed-survivor and balanced-panel subsamples), where the result holds or strengthens (t ≈ 3.3). The direction of this bias is not fully resolved without a survivorship-free dead-fund overlay. The survivor-hardened subsamples are reassuring, and the allocator use-case — ranking among extant candidate funds — is partly insulated, but the definitive test is to add liquidated, merged, and renamed funds in a future revision (Appendix A.1).
- Modest sample. The test rests on ~15 annual rebalances. The trailing feature is persistent (autocorrelation ≈0.82) — the very persistence being documented — but the t is built on the non-overlapping annual Q5−Q1 gap series, whose own autocorrelation is ≈0.1, so the simple annual t uses the appropriate denominator (Section 4; Appendix A.4, A.8).
- The adaptive-hedge refinement is a reliability gain, not a larger edge. The adaptive (L-Star) residual sharpens the skill signal once style is stripped (Section 5), but on a raw basis it trails the fixed residual, and its with/without comparison sits on the shorter, momentum-bound 2014–2024 window. We present it as a refinement of the ranking residual, not as a replacement for the §4 persistence headline.
Final framing
What this work claims is narrow and, we think, useful: if you are going to select an active manager inside a chosen mandate, the decomposition tells you which part of their record is worth selecting on, and the answer — out of sample, on legible statistics — is stock-picking, measured style- and sector-neutral, and treated as durable quality. The underlying RiskModels decomposition lets allocators apply this framework to their own mandates and candidate lists.
Data & verification. Our own statistics are computed in-house on the cohort and panel described in Appendix A and are stated plainly. External comparisons are directional unless explicitly stated otherwise, because the cited studies differ in universe, period, signal construction, and return definition. Third-party figures cited in the comparison table were checked against the referenced source materials as of June 2026.
Appendix A. Methodology
A.1 Sample construction
Cohort definition (at each rebalance). The cohort is, at each rebalance, SPY-benchmarked (BW-BENCH-SPY) US equity funds with coverage-quality "high" or "medium." The intended universe is diversified US equity; after the SPY-benchmark and name filters the realized cohort is effectively entirely the large-cap-blend group (the panel's style_group field is a coverage-derived tag, not a prospectus label, so style breadth is enforced by fund-name filtering rather than a reliable style classifier). Sector, specialty, international, and passive products are excluded by name. The numbers therefore characterize a large-cap US-blend cohort specifically. This yields 220 funds total across the sample, 15 annual rebalances, with 72–214 funds per cross-section (median 157), over 2006–2026.
Rebalance convention. Each rebalance is taken at each calendar year's last available observation — annual and strictly non-overlapping.
Feature and outcome windows. The ranking feature is the trailing-36-month mean of the relevant skill (minimum 24 monthly observations required); the outcome is the forward 12 months.
Decomposition engine. The underlying engine runs a bottom-up cascade on a security-level universe of ~6,300 distinct securities including delisted names across ~5,000 trading days, decomposing every stock, every day, into market/sector/subsector layers (the "sector cascade") and market/size/value layers (the "Fama–French cascade"). Stock residuals are aggregated to funds through their actual reported point-in-time holdings — SEC N-PORT for recent history and a restored N-Q deep history before 2019. The fund cohort, however, is drawn from funds that exist as of the panel's final date and is back-filled through history; it therefore does not include funds liquidated, merged, or renamed before the panel end, and is subject to survivorship and backfill bias. We bound this by re-running on survivorship-hardened subsamples — funds present from the panel start (first observation ≤ 2006) and the balanced panel present at every rebalance — where the gap holds at roughly +2.3 to +2.9pp and the t if anything rises (to ≈ 3.3); the result also survives dropping the bottom quintile entirely, so it is not an artifact of truncating poor performers. The direction of this bias is not fully resolved without a survivorship-free dead-fund overlay. The survivor-hardened subsamples are reassuring, and the allocator use-case — ranking among funds one is actively choosing between, which are by construction extant — is partly insulated, but the definitive test is to add liquidated, merged, and renamed funds in a future revision. Holdings are carried forward only from their filing date (point-in-time): a fund's residual in any month uses only positions an investor could have known at the time. This conservative carry-forward rule is a deliberate methodological strength — it forecloses any look-ahead through the holdings panel, at the cost of treating holdings as static between filings.
The broader panel from which the cohort is gated contains on the order of ~170,000 coverage-gated fund-months across ~1,000 funds; the manager-selection tests in Sections 4–5 run on the diversified SPY-benched cohort described above.
Subsector is the finer industry grouping one level below sector.
A.2 The decomposition
Each fund's return in month t is rebuilt as the holdings-weighted sum of its stocks' decomposed returns, using only positions known as of t (point-in-time):
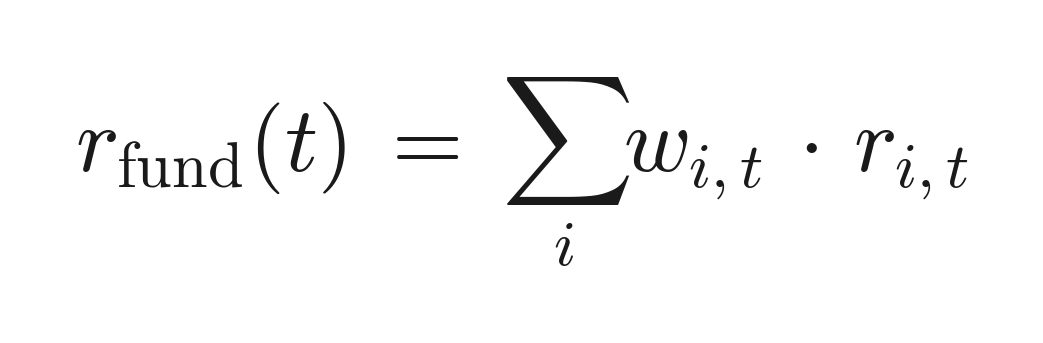
with the weights w_i,t taken from the latest filing on or before t.
Each stock's daily return is decomposed two ways. The two cascades produce two residuals:
-
Sector-cascade residual — the part of return orthogonal to industry structure:
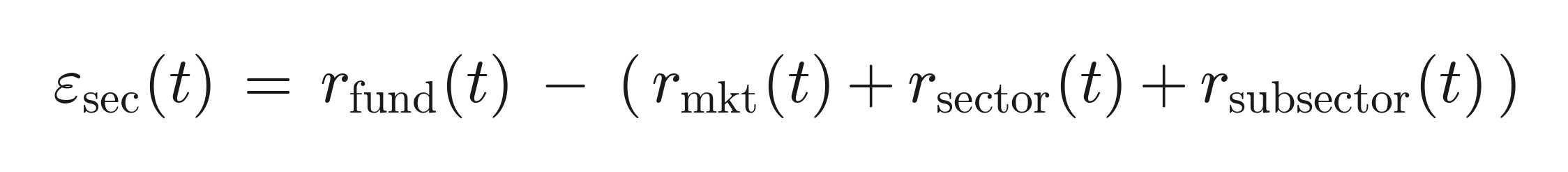
-
Fama–French-cascade residual — the part orthogonal to style:
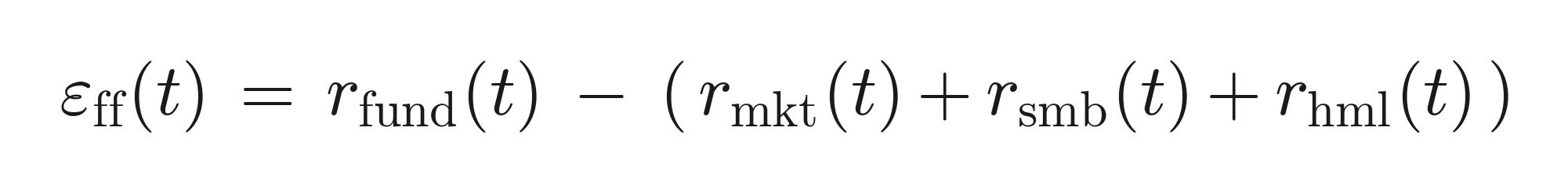
-
Genuine ("doubly-cleaned") stock-picking — the part orthogonal to both industry structure and style:
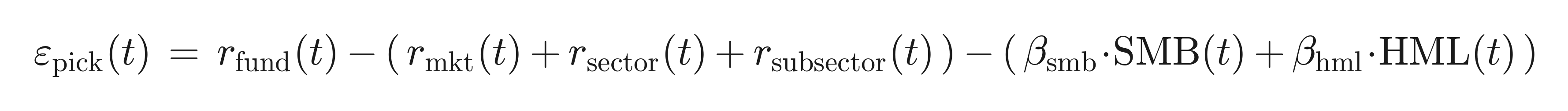
This is the target for "genuine skill" throughout.
Point-in-time style neutralization. Style is stripped strictly point-in-time. For each fund and month t, the rolling factor betas are estimated by OLS on a strictly trailing 36-month window ending at t (no look-ahead):
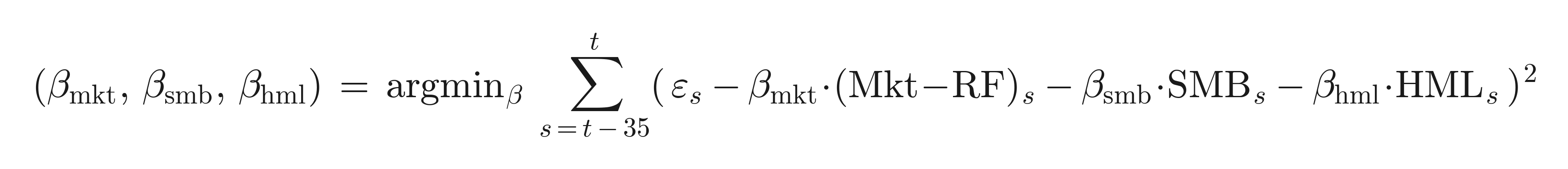
and the style-neutral residual is that residual minus its fitted style component:
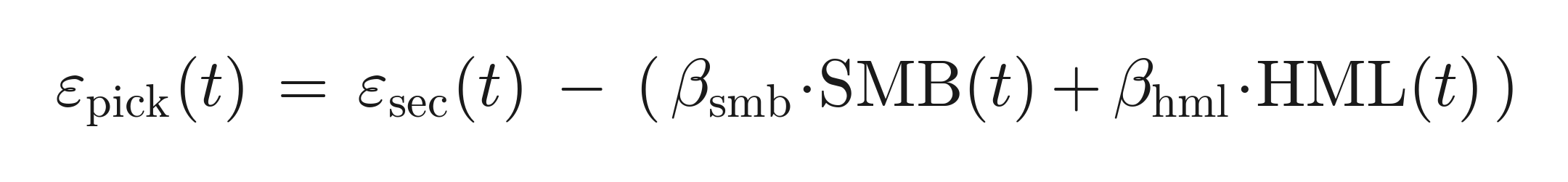
Because the window ends at t, the neutralization uses only information available at the time.
A.3 The three skill axes
The three manager skills tested in Section 4 are constructed from the cascade layers (the market/beta layer is excluded — it is not a selectable skill):
- Style timing = the fund's size/value contribution (β_smb·SMB + β_hml·HML) inside the residual. Section 4 further decomposes this into a static tilt (β̄·factor, using the fund's own mean exposure) and a timing component ((β_t − β̄)·factor); the anti-persistence lives in the timing component, with the static tilt neutral.
- Sector/subsector timing = the ERM3 sector and subsector layers (systematic return net of the market layer).
- Stock picking = the style-neutral residual (residual net of size/value).
A.4 The test: train → predict → roll-forward
The headline design is an annual, non-overlapping train → predict → roll-forward. At each year-end, funds are ranked by their trailing-36-month skill at the relevant axis (point-in-time). The next 12 months' top-quintile-minus-bottom-quintile (Q5 − Q1) contribution in the relevant payoff space is recorded. This repeats across 15 annual rebalances. The reported "score" is the simple t-statistic — mean over standard error — of that annual gap series. We deliberately use this legible annual t rather than information-ratio or bootstrap statistics as the headline; the latter, when applied to overlapping monthly windows, inflate significance and do not annualize cleanly.
Effective sample size and multiple testing. The trailing ranking feature is persistent — its 1-year rank autocorrelation is ≈ 0.82 — which is the persistence we are documenting, not a defect. The statistic itself is built on the non-overlapping annual Q5−Q1 gap series, whose own year-to-year autocorrelation is ≈0.1, so the simple annual t uses the appropriate denominator. A stationary block-bootstrap on those gaps (respecting their mild dependence) gives P(mean ≤ 0) ≈ 0.001. We retain humility about the modest 15-rebalance sample, but the feature autocorrelation does not deflate this t. On multiple testing: the design evaluates three skills (Section 4) plus a ranking bake-off (Section 5), a context worth stating, but these were conceptually pre-specified — the three skills are the exhaustive decomposition of what a manager does (style timing, sector timing, stock selection), not a search across many candidate signals. The stock-picking persistence survives this correction: raw two-sided p ≈ 0.013 → adjusted p ≈ 0.039 under Bonferroni, Holm, and Benjamini–Hochberg (m = 3), still significant at 5%.
A.5 Level vs timing (the fixed-effects test)
To separate durable quality from timing, we work at the level of each fund's monthly time series of its feature and its target — both already fund-level residual series, not individual positions. For each fund we subtract that fund's own full-sample mean from its monthly feature series and, separately, from its monthly target series (a within-fund / fixed-effects demeaning applied to the fund-level residual series, not a position- or holdings-level operation). What remains for each fund is the deviation of each month from its own long-run average — the time-varying component — with the fund's permanent level removed. For stock-picking, the within-fund signal is essentially zero (within-fund t ≈ 0) while the pooled signal is significant — so the persistence is a between-fund level effect: some funds are persistently better pickers, rather than any fund switching its picking on and off. (A static, full-sample-mean sort — which carries zero timing information — reproduces the large majority of the pooled spread, confirming the level interpretation.) This is why the allocator prescription is "pick the persistently good and hold," not "time the hot hand."
A.6 The bake-off and the CCP head-to-head (with caveats)
Bake-off (subsector vs sector-only). Identical pipeline on the same ~218 diversified funds, annual non-overlap, both sides style-neutralizing the ranking signal to isolate the industry-depth question, predicting the same genuine-skill target. Result: sector-only +2.10pp (t = 1.91) vs subsector +2.21pp (t = 2.20). Subsector depth reduces noise and lifts reliability across the significance line; it does not enlarge the edge. A refinement, not the headline. (Both figures sit a touch below the +2.7pp headline range precisely because they style-neutralize the feature; ranking on the raw residual feature is the better practice — see A.2 and Section 5.)
CCP "company they keep" head-to-head. We implemented Cohen-Coval-Pastor on our cohort: a fund's skill proxy is its trailing-36-month CAPM alpha; a stock's "quality" is the holdings-weighted average skill of its holders; a fund's CCP score is the holdings-weighted average quality of its stocks, computed leave-one-out. On the same ~218-fund cohort and period, predicting forward genuine (style-neutral) skill, the CCP score scored t ≈ 0.7 (≈ noise) while our style-neutral residual scored t ≈ 2.2 and our raw residual t ≈ 3.8. Caveat (important): CCP is handicapped by a homogeneous large-blend cohort — its consensus mechanism needs a broad, heterogeneous universe to discriminate, and on a cohort where everyone holds the same mega-caps the consensus is near-identical across funds. The consensus here was also computed over only ~220 funds (thin) and on a different period than Morningstar's published test. So this is not "we beat CCP/Morningstar everywhere"; it is "for the homogeneous-cohort decision an allocator actually faces, our signal sorts and theirs cannot." A fairer test would recompute the CCP consensus over a broad universe (all styles) while evaluating on the cohort.
A.7 Capacity
Year-over-year top-quintile retention is ~59% (turnover ~41%/yr → implied mean holding ≈ 2.4 years). For a manager-allocation signal this is highly tradeable — re-allocation roughly every 2.4 years sits well inside fund lock-up and redemption constraints — and the slow 36-month feature gives durable selection.
A second, distinct dimension of tradability sits one level down, at the holdings level: how slowly the underlying positions turn. The manager-ranking turnover above measures how often an allocator re-sorts funds; position retention measures how stable each fund's own portfolio is between filings. The signal is built on a trailing-36-month residual aggregated through point-in-time holdings that are themselves persistent, so the feature does not swing on quarter-to-quarter position churn. Slow underlying-holdings turnover reinforces the slow re-allocation cadence: both the ranking and the positions that generate it move gradually, which is what makes the signal practical to act on rather than a high-frequency trade.
A.8 Honest caveats
- The defensible significance is the annual, non-overlapping, simple-t statistic. The headline configuration — ranking on the raw sector-cascade residual feature against a style-neutral target (the best practice of Section 5) — is +2.7pp forward Q5−Q1 at t ≈ 2.8, and this is the single number used throughout the paper. A stricter all-style-neutral configuration (style-stripping the feature as well) lands a touch lower (≈ +2.2pp, t ≈ 2.2), which is why the bake-off figures in A.6 sit below the headline. An earlier framing of this work used a Newey–West t on overlapping monthly windows together with a monthly information ratio; adversarial re-review showed those overstated the result — the "monthly" observations were overlapping twelve-month windows that do not annualize cleanly, and a large part of the apparent signal was a permanent level difference between funds rather than a timed bet. Those statistics are deliberately not used here; the conservative annual t is.
- Stock-picking persistence is a between-fund level effect, not a timing signal an allocator must catch in motion (A.5).
- The 1-year feature-rank autocorrelation is high (≈0.82) — which is the persistence we are documenting, not a defect — but the t is built on the non-overlapping annual Q5−Q1 gap series (own autocorrelation ≈0.1), so the simple annual t uses the appropriate denominator and the feature autocorrelation does not deflate it (full statement in A.4).
- Part of the negative style-timing signal reflects the tendency of a rolling exposure's deviation from its own mean to revert toward it; either way, the allocator conclusion (don't credit recent style timing) is unchanged.
- This signal lives on the gross / holdings-derived side, where skill demonstrably survives. The Berk-Green caveat stands: the rents to genuine skill may accrue to managers rather than investors.
- The adaptive-hedge (L-Star) residual is included (Section 5; construction and the out-of-sample leakage check in A.9). An earlier explained-ratio issue in cloned pre-launch ETF history (XLC, XLRE) has been resolved in the cascade; the L-Star results here run on the current, materialized cascade, whose PIT-safe, GBM-based selection algorithm is a point-in-time refinement to the ranking feature.
A.9 The adaptive-hedge residual (L-Star)
Construction. The fixed sector cascade hedges every stock to the deepest level (market → sector → subsector). The adaptive residual instead lets a cost-aware, PIT-safe, GBM-based selection algorithm choose each stock's hedge depth (market, market+sector, or market+sector+subsector) to maximize predicted out-of-sample risk reduction net of hedging cost, rather than always hedging to the deepest level. It is computed point-in-time — a refinement to the ranking feature, not the headline persistence result.
Why it can read cleaner after style-stripping. Because the selector optimizes cost-efficient risk removal rather than strict factor-neutrality, the raw adaptive residual co-moves slightly more with contemporaneous sector/subsector timing than the fixed full-depth residual — which is why it trails on the raw number. The question for a skill claim, though, is whether that shows up as inflated forward spread. It does not.
Out-of-sample leakage check. Mirroring the persistence construction, we purged the forward return of contemporaneous (same-window) sector and subsector timing — a per-year cross-sectional residual of the forward return on forward sector/subsector timing — and re-measured the adaptive residual's forward Q5−Q1 spread. The advantage is essentially intact after the purge (it retains the large majority of its edge and stays at or above the fixed residual), and a predictive Fama–MacBeth test finds no channel (t ≈ 0) by which the trailing ranking feature forecasts future sector timing. We therefore read the adaptive residual's larger forward spread as genuine stock selection, not sector-timing riding along. The in-sample contemporaneous co-movement is a true but differently-scoped diagnostic; on the forward, out-of-sample footing the paper cares about, it does not translate into spread inflation.
Windows. The with/without-L-Star comparison in Section 5 is on the common 2014–2024 sample (eleven annual rebalances) that the momentum leg requires; the effective-sample caveat of Section 4 applies. The comparison establishes the relative sharpening from adaptive hedging, not a replacement for the §4 headline.
Sources
Fund documents (Section 1)
Quotes and disclosed statistics verified against primary materials (accessed June 2026):
- AGTHX — The Growth Fund of America (Capital Group fund page): objective "to provide you with growth of capital." Disclosed 3-year risk stats as of 5/31/26: beta 1.18, alpha −0.47, std. dev. 16.14%, Sharpe 1.26 — all vs the S&P 500 Index (the fund's stated benchmark). https://www.capitalgroup.com/individual/investments/fund/agthx
- FCNTX — Fidelity Contrafund (fact sheet, Mar 31 2026): objective "The investment seeks capital appreciation." Strategy "invests in securities of companies whose value the advisor believes is not fully recognized by the public … in either 'growth' stocks or 'value' stocks or both." Benchmark S&P 500 TR USD; no beta/alpha disclosed — only a 1–5 risk dial and Morningstar category risk. Holdings snapshot: Tech 25.8%, Comm. Svcs 22.2%; top 10 = 47% of assets. https://workplace.vanguard.com/assets/corp/fund_communications/pdf_publish/us-products/fact-sheet/F0375.pdf
- FCNTX SEC summary prospectus (Form 497K, FY2023): https://www.sec.gov/Archives/edgar/data/0000024238/000002423823000023/filing5692.htm
- AGTHX SEC summary prospectus (Form 497K, FY2010): https://www.sec.gov/Archives/edgar/data/0000044201/000004420110000056/gfa497k.htm
- Fund betas computed from in-house yfinance NAV total-return series vs the SPY market series; the 3-year AGTHX figure (1.20) reproduces Capital Group's reported 1.18.
Conventional tools (Section 2)
- Morningstar Portfolio X-Ray (holdings look-through): https://developer.morningstar.com/direct-web-services/documentation/direct-web-services/portfolio-x-ray/overview
- Morningstar Direct — Equity Performance Attribution methodology (Brinson-style): https://morningstardirect.morningstar.com/clientcomm/Morningstar-Equity-Performance-Attribution-Methodology.pdf
- Morningstar Global Risk Model methodology (36 factors: 8 style + 11 sectors + region + currency; 5-yr rolling regression; security specific return): https://www.morningstar.com/content/dam/marketing/shared/Company/Products/Direct_Cloud/RiskModel_Global_Methodology.pdf
- On Brinson's inability to separate style/factor influences from selection: SimCorp, https://www.simcorp.com/resources/insights/industry-articles/2024/Risk-based-or-Brinson-attribution; FactSet, https://insight.factset.com/how-a-multi-factor-attribution-framework-can-provide-a-deeper-insight-into-the-sources-of-relative-performance
Competitive landscape (Section 6)
Morningstar
- "The Best Predictor of Stock-Fund Performance" (Rekenthaler; holdings-based, style-adjusted, ≈ +330 bps): https://www.morningstar.com/columns/rekenthaler-report/best-predictor-stock-fund-performance
- Global Risk Model methodology: https://www.morningstar.com/content/dam/marketing/shared/Company/Products/Direct_Cloud/RiskModel_Global_Methodology.pdf
- Equity Performance Attribution methodology: https://morningstardirect.morningstar.com/clientcomm/Morningstar-Equity-Performance-Attribution-Methodology.pdf
Consultants
- Callan, "Active Share Is Not a Litmus Test": https://callan.com/blog-archive/active-share · active/passive framework: https://www.callan.com/blog-archive/active-or-passive/
- Russell Investments, investment approach: https://russellinvestments.com/us/about-us/our-investment-approach
- NEPC, Extension Strategies: https://www.nepc.com/wp-content/uploads/2025/04/Extension-Strategies-Come-Into-Their-Own.pdf
- Mercer GIMD guide (A/B/C): https://www.mercer.com/content/dam/mercer/attachments/global/gl-2019-global-investment-manager-database-guide.pdf
- Cambridge Associates, Hallmarks of Successful Active Equity Managers: http://www.etfmodelsolutions.com/wp-content/uploads/2014/04/Hallmarks_of_Successful_Active_Equity_Managers_2013.pdf · VantagePoint 2024: https://www.cambridgeassociates.com/wp-content/uploads/2024/05/2024-05-VantagePoint-Building-Resilient-Public-Equity-Portfolios-3.pdf
- Aon, Buy/Qualified/Sell + ESG ratings: https://insights-north-america.aon.com/defined-benefit/aon-introduces-qualitative-esg-ratings-for-buy-rated-funds
Industry & academic context
- S&P SPIVA Persistence Scorecard (YE2024): https://www.spglobal.com/spdji/en/documents/spiva/persistence-scorecard-year-end-2024.pdf · SPIVA US Scorecard YE2023: https://www.spglobal.com/spdji/en/documents/spiva/spiva-us-year-end-2023.pdf
- Jenkinson, Jones & Martinez (2016), "Picking Winners? Investment Consultants' Recommendations of Fund Managers," Journal of Finance: https://www.umass.edu/preferen/You%20Must%20Read%20This/PickingWinners.pdf
Academic literature (holdings-based skill, factor/sector neutralization, persistence)
Our method's building blocks are each well-established — which both reassures (the approach rests on accepted foundations) and clarifies what is novel. We are not aware of a published paper that combines all four of: holdings-based, factor-neutral, sector/industry-neutral by construction, and out-of-sample persistence-validated. Sector neutralization as an explicit construction axis appears to be the missing piece across the literature we surveyed. The closest prior art is Fang-Lee (2026) and Wermers-Yao-Zhao (2012); the one explicit-sector treatment (Busse-Tong) is attribution, not a tradable signal. We frame our contribution as a novel synthesis building on DGTW / Busse-Jiang-Tang (factor + characteristic precedent) and Busse-Tong (industry decomposition) — not a from-scratch invention. We deliberately do not rely on Active Share, which Frazzini-Friedman-Pomorski (2016) argue is a small-cap-benchmark artifact.
- Daniel, Grinblatt, Titman & Wermers (1997), characteristic selectivity (DGTW): https://terpconnect.umd.edu/~wermers/ftpsite/Dgtw/dgtw.pdf
- Busse, Jiang & Tang (2021), "Double-Adjusted Mutual Fund Performance" (factor + characteristic, persistence): https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2516792
- Wermers, Yao & Zhao (2012), holdings → implied stock alphas: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=891728
- Busse & Tong, "Mutual Fund Industry Selection and Persistence" (explicit sector decomposition): https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1065701
- Fang & Lee (2026), "Stocks Through a Looking Glass" (style-segment holdings signal; Accounting & Finance) — closest prior art
- Kacperczyk, Sialm & Zheng (2005), industry concentration: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=353420
- Cohen, Polk & Silli (2010) / Antón, Cohen & Polk (2021), "Best Ideas": https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1364827
- Cremers & Petajisto (2009), Active Share: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=891719; critique — Frazzini, Friedman & Pomorski (2016), "Deactivating Active Share": https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2597122
- Ferson & Mo (2016), selection vs timing vs vol-timing: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2022142
- Berk & van Binsbergen (2015), value added persists: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2038108; Harvey & Liu (2018), "Detecting Repeatable Performance": https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2691658
- Cohen, Coval & Pástor (2005), "Judging Fund Managers by the Company They Keep" (the CCP consensus signal)
- Kaniel, Lin, Pelger & Van Nieuwerburgh (2023), ML the skill of fund managers: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3977883; DeMiguel et al. (2023), ML fund selection (long-only alpha contested): https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3768753
Verification note: external comparisons here are directional unless explicitly stated otherwise, because the cited studies differ in universe, period, signal construction, and return definition. The third-party figures cited in the Section 6 comparison table were checked against the referenced source materials as of June 2026; the broader academic citations (e.g., Petajisto's spread, Kacperczyk-Sialm-Zheng decile spreads, Fang-Lee) are referenced for context, with specific figures stated qualitatively where the original studies' exact values are not reproduced here. Our own numbers are computed in-house and are stated plainly.